La fonction Remplacer tout d'EMu est utilisée pour effectuer des changements sur plusieurs enregistrements. Elle permet d'appliquer la même mise à jour à un ensemble d'enregistrements sélectionnés. Remplacer tout applique une chaîne ou un modèle fourni par l'utilisateur à un champ particulier. En cas de correspondance, le texte est remplacé par une autre valeur fournie par l'utilisateur. Le point important ici est que la chaîne ou le modèle saisi par l'utilisateur est comparée aux données d'un champ donné telles qu'elles sont stockées sur le serveur, c'est-à-dire telles qu'elles sont spécifiées par l'entrée de Registre Supported : toute chaîne ou modèle fourni pour le remplacement doit donc suivre ce même ordre. Afin d'appliquer cette restriction, la fonctionnalité suivante s'applique à la fonction Remplacer tout :
- La fonction Remplacer tout est désactivée sauf si l'option Toutes les langues est sélectionnée pour le paramètre de Langue des données : en d'autres termes, la commande de Remplacer ne peut pas être appelée lors de l'affichage des données dans une seule langue.
La raison de cette restriction est que toute chaîne ou tout modèle utilisé pour trouver le texte à remplacer est recherché dans la valeur complète du champ, et pas seulement dans la langue actuelle des données. Par exemple, pour remplacer le mot total par aggregate dans un système EMu anglais/français, la fonction Remplacer tout localisera toutes les occurrences de total et les remplacera par aggregate, quel que soit l'endroit où le texte apparaît dans les données. Ainsi, lorsque total apparaît dans le texte français, il est remplacé par le mot anglais aggregate. Cela signifie qu'un utilisateur pourrait modifier les valeurs dans une autre langue que celle affichée actuellement. Afin d'éviter ce problème, la fonction Remplacer tout n'est pas disponible lors de l'affichage dans une seule langue.
- La fonction Remplacer tout est désactivée lorsque l'option Toutes les langues est sélectionnée comme paramètre de Langue des données et lorsque le paramètre Ordre d’affichage de la langue est différent de celui défini par l'entrée de Registre Supported (affichée dans le champ Ordre système dans l'onglet Langue de la fenêtre Options).
La raison de cette restriction est qu'il n'est pas toujours possible de traduire les chaînes ou les motifs saisis avec des paramètres d'ordre d'affichage arbitraires en valeurs appropriées pour le remplacement. Par exemple, dans un système anglais/français avec un Ordre d'affichage français/anglais, la chaîne/le modèle total;:; ne peut pas être converti en un modèle unique à appliquer aux données Anglais/Français stockées dans EMu. La chaîne de caractères / modèle signifie qu'il faut rechercher le mot total lorsqu'il s'agit du dernier mot français (car un délimiteur de langue a été saisi à la fin). Une solution possible consiste à traduire la chaîne / modèle par Français$ pour que le Français soit le dernier mot des données. Cependant, une telle chaîne/un tel modèle correspondrait aux données suivantes :
- Français
- Anglais;:;Français
En d'autres termes, les données anglaises peuvent être modifiées là où seules les modifications françaises étaient prévues. Il existe un certain nombre d'autres modèles problématiques car ils ne peuvent pas être convertis en un modèle adapté aux données Anglais/Français. Afin d'éviter la mise à jour accidentelle de valeurs non prévues, la fonction Remplacer tout n'est activée que pour les utilisateurs qui consultent dans Toutes les langues et dont l'Ordre d'affichage des langues est le même que celui défini par entrée de Registre Supported.
Ces exemples assument un environnement bilingue dans lequel les données sont stockées sur le serveur en anglais, puis en français.
Note: Voir Remplacer Tout pour plus de détails sur la définition d'une substitution ; voir Caractères génériques dans Remplacer Tout pour une description des caractères génériques utilisés dans ces exemples.
|
1.
|
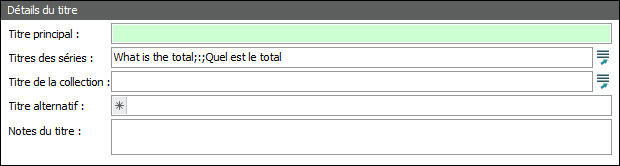
Objectif |
Rechercher dans le champ Titres des séries (Détails du titre) la première occurrence du mot total et le remplacer par le mot amount. |
|
Données originelles |
|
|
|
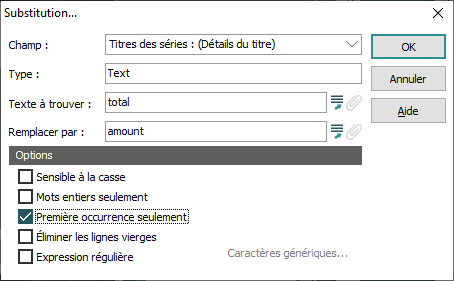
Substitution |
|
|
|
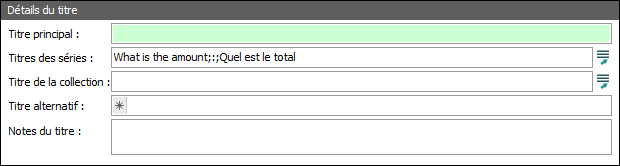
Résultat |
|
|
|
Description |
Sélectionner Première occurrence seulement dit à EMu de rechercher la première occurrence du mot total et de le remplacer par le mot amount et puis d'arrêter. |
|
|
2.
|
Objectif |
Cet exemple démontre les « greedy patterns » en fonctionnement. Un « greedy pattern » est un « pattern » qui fait correspondre la plus longue chaîne possible. (.*) est un exemple « greedy pattern », bien que de façon plus générale, l'utilisation du caractère générique * initiera une correspondance « greedy pattern ». Lorsque le Texte à trouver inclut un « greedy pattern », le « pattern matching » dans le champ cible trouvera la séquence correspondante la plus longue. Ici, nous recherchons dans le champ Titres des séries (Détails du titre) le mot français total (c’est-à-dire, total apparaît après le délimiteur des langues) et le remplaçons par montant. |
|
Données originelles |
|
|
|
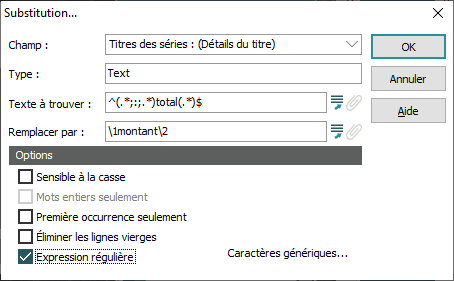
Substitution |
|
|
|
Résultat |
|
|
|
Description |
Texte à trouver
Saisir le texte à trouver (total) et les expressions entre ^ (qui indique le début du champ) et $ (qui marque la fin du champ) indique que nous recherchons (et remplaçons) sur le contenu entier du champ. Il y a deux expressions dans cet exemple, marquées par les parenthèses :
Remplacer par \1montant\2 Dans cette utilisation, le \ n'effectue pas une fonction de caractère d'échappement (comme dans \? qui signifie traiter ? comme un point d'interrogation, et non comme un caractère avec une fonction spéciale). \1 réfère à la première expression dans le champ Texte à trouver :(.*;:;.*) \2 réfère à la seconde expression dans le champ Texte à trouver : (.*) Dans ce cas EMu doit localiser et remplacer : ^(.*;:;.*)total(.*)$ avec : (Expression 1) montant (Expression 2) Autrement dit : (What is the total;:;Quel est le) montant( ) |
|
|
3.
|
Objectif |
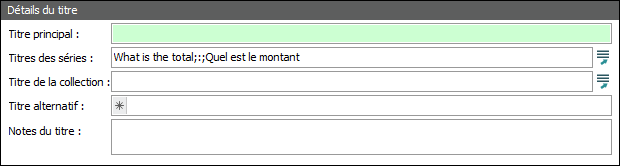
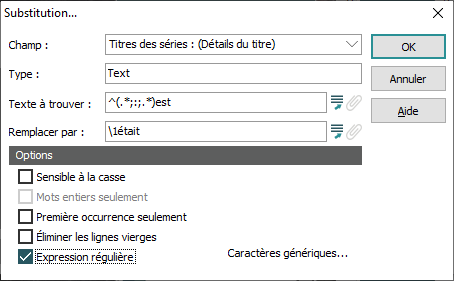
Rechercher dans le champ Titres des séries (Détails du titre) le mot français est et le remplacer par était. |
|
Données originelles |
|
|
|
Substitution |
|
|
|
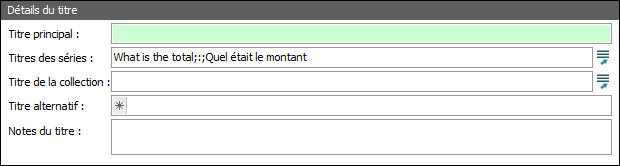
Résultat |
|
|
|
Description |
Texte à trouver ^(.*;:;.*)est La première chose à remarquer est que nous ne remplaçons pas le contenu entier du champ puisque notre Texte à trouver n’est pas entre ^ et $. Il n'y a qu'une seule expression et elle affecte les données à partir du mot à remplacer (est) jusqu’au début du champ (une fois encore cela implique un « greedy pattern » qui correspond à la séquence la plus longue possible). Notre Texte à trouver indique à EMu de tout faire correspondre depuis la dernière occurrence de est jusqu'au début du champ. En regardant ça de plus près :
Remplacer par \1était \1 réfère à la première expression dans le champ Texte à trouver :(.*;:;.*) Dans ce cas EMu doit localiser et remplacer : ^(.*;:;.*)est avec : (Expression1) était Tout le reste dans le champ après est n’est pas touché. Autrement dit : (What is the total;:;Quel) était le total |
|
|
4.
|
Objectif |
Cet exemple démontre les « greedy patterns » en fonctionnement dans un cadre plus complexe. |
|
Données originelles |
|
|
|
Substitution |
|
|
|
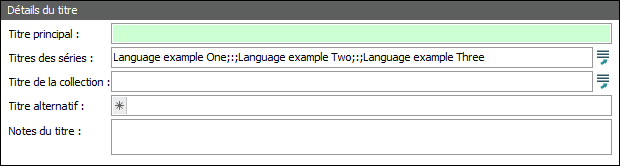
Résultat |
|
|
|
Description |
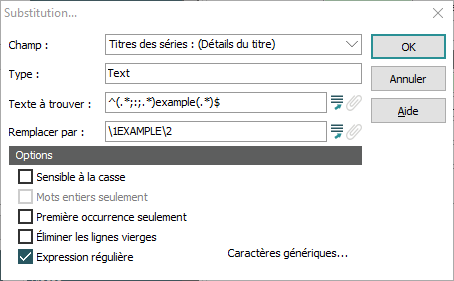
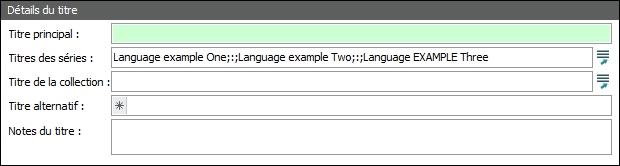
Si nous n'étions pas conscients que l'utilisation du « greedy pattern » (.*) traite une correspondance de la fin du champ au début, on pourrait s'attendre à ce que cette substitution remplace le deuxième example, nous donnant : Language example One;:;Language EXAMPLE Two;:;Language example Three Au lieu de cela, ce qui suit se produit : Texte à trouver En commençant à partir de la fin du champ (.*), qui est Expression 2, correspond à tout jusqu'à example, c’est-à-dire : Three Puisqu’un « greedy pattern » (.*) correspond à la séquence la plus longue possible, ce qui dans ce cas est tout à partir de la fin du champ jusqu'à la dernière occurrence de example, qui est le texte à remplacer par EXAMPLE. ^(.*;:;.*), qui est Expression 1, correspond à tout de ce point au début du champ, c’est-à-dire : Language example One;:;Language example Two;:;Language En regardant ça de plus près :
Remplacer par \1EXAMPLE\2 \1 est la première expression, ce qui équivaut à : Language example One;:;Language example Two;:;Language \2 est la seconde expression, ce qui équivaut à : Three Ce qui nous donne : Language example One;:;Language example Two;:;Language EXAMPLE three |